「自然言語処理を用いたアッカド語楔形文字の読解」という論文を見つけました。著者はイスラエルはアリエル大学のシャイ・ゴルディンさんを筆頭に7名。この人数の多さに工学部みを感じるわけですが(偏見)、実際にはコンピュータサイエンスのひとが一人いるだけで残りは人文系なんでしょうか? 掲載誌はオープンアクセスジャーナルです。ありがたーい。
Gordin S, Gutherz G, Elazary A, Romach A, Jiménez E, Berant J, et al. (2020) Reading Akkadian cuneiform using natural language processing. PLoS ONE 15(10): e0240511. https://doi.org/10.1371/journal.pone.0240511 (opens new window)
ゴルディンさん達は、この論文で自然言語処理の技術を使いアッカド語楔形文字の自動翻字に取り組んでいます。
メソポタミアで使われた楔形文字は表意文字としても表音文字としても使われますが、日本語での漢字の使われ方と同様にひとつの文字が多くの音価を持っていることが特徴です。ですから、楔形文字で書かれた文章をどう読むかは文脈に大きく依存します。しかし、アッカド人の書記にとってはそれほど難しくはなかったものと想像されます。例えば私たちが「東日本橋」という駅名を読むことを考えてみてください。この4つの漢字はそれぞれの文字がいくつもの読みを持っています。それでも、例えこの地名をしらなくてもその多くの読み方の組み合わせの中で「ひがしにほんばし」という読み方が一番自然に感じられますよね。
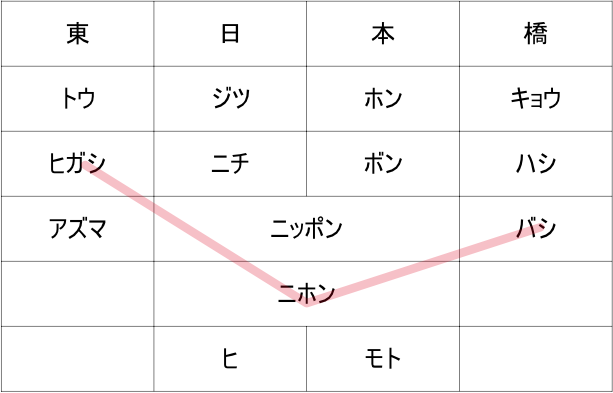
それは例えば「日本」は一単語の可能性が高い、とか、地名の先頭に東西南北の文字が出てきたら訓読みしがち、とかの経験則を組み合わせた感覚によるものです。楔形文字についても、楔形文字表記とその読みの表記を大量に学習させることで、明示的に文法を教えなくてもなんとなく自然な読み方を学習できるのではなかろうか、というのがこういった研究の基本的なアイデアです。たぶん。
データの学習元にはOraccのRINAP (opens new window)(新アッシリア時代の王碑文データベース)を使っているようです。古代オリエント界隈は遥かな昔、西暦2000年前後くらいからデジタル化資料が豊富に蓄積されていて、一般に公開されており、しかもそれらが機械可読であるのみならずTEIのようなメタデータのマークアップも適切に付加されているまさに宝の山です。きっとこの土壌からは今後もいろんな研究が芽吹くのでしょうね。
すばらしいことにこの研究の成果もgithub (opens new window)で公開されており、さらには簡単に試すためのデモサイトもつくられています。
Babylonian Engine website (opens new window)というのがそれです。
このサイトではATRAHASIS(楔形文字の文章の損傷部分を推測して補完するプロジェクト)とAKKKADEMIA(楔形文字の自動翻字プロジェクト)の2つのプロジェクトのデモンストレーションが公開されています。ここではAKKADEMIAを選択しましょう。なおこのサイトはHerokuというプラットフォームで公開されています。おそらくは無料プランをつかっていて、その場合はアプリケーションへのアクセスが一定時間なくなると自動的にスリープされる仕組みになっています。ですから、最初にアクセスしたときには応答があるまで少し時間がかかります。少しだけ待ってあげてくださいね。
さて、どれくらいの実力があるのでしょうか。
新アッシリア版の「ネルガルとエレシュキガル」の冒頭1行で試してみましょう。
𒂊𒉡𒈠𒀭𒈨𒌍𒅖𒆪𒉡𒆠𒊑𒂊𒋫
e-nu-ma DINGIR.MEŠ iš-ku-nu qé-re-e-ta
神々が宴を催したとき、
Nergal And Ereškigal (SAACT VIII)
です。まずここでポイントとなるのは「神々」という意味のシュメログラム𒀭𒈨𒌍DINGIR.MEŠを正しく読めるかというところでしょうか。とくにMEŠはユニコードでは符号が割り当てられておらず、U+12228 CUNEIFORM SIGN ME U+1230D CUNEIFORM SIGN U U Uの2符号で表現しているわけですが、果たしてどのように読んでくれるのでしょうか。また後半の𒆠𒊑𒂊𒋫qé-re-e-taでは、𒆠はkiという読みが最も一般的なところですから、文脈から正しい読みを判定できるのかどうかがポイントになってきますね。
というわけで実際に試してみましょう。Akkademiaの入力欄にこの楔形文字を貼り付けると、自動的に変換が始まるようです。そして数十秒の処理時間の後……。
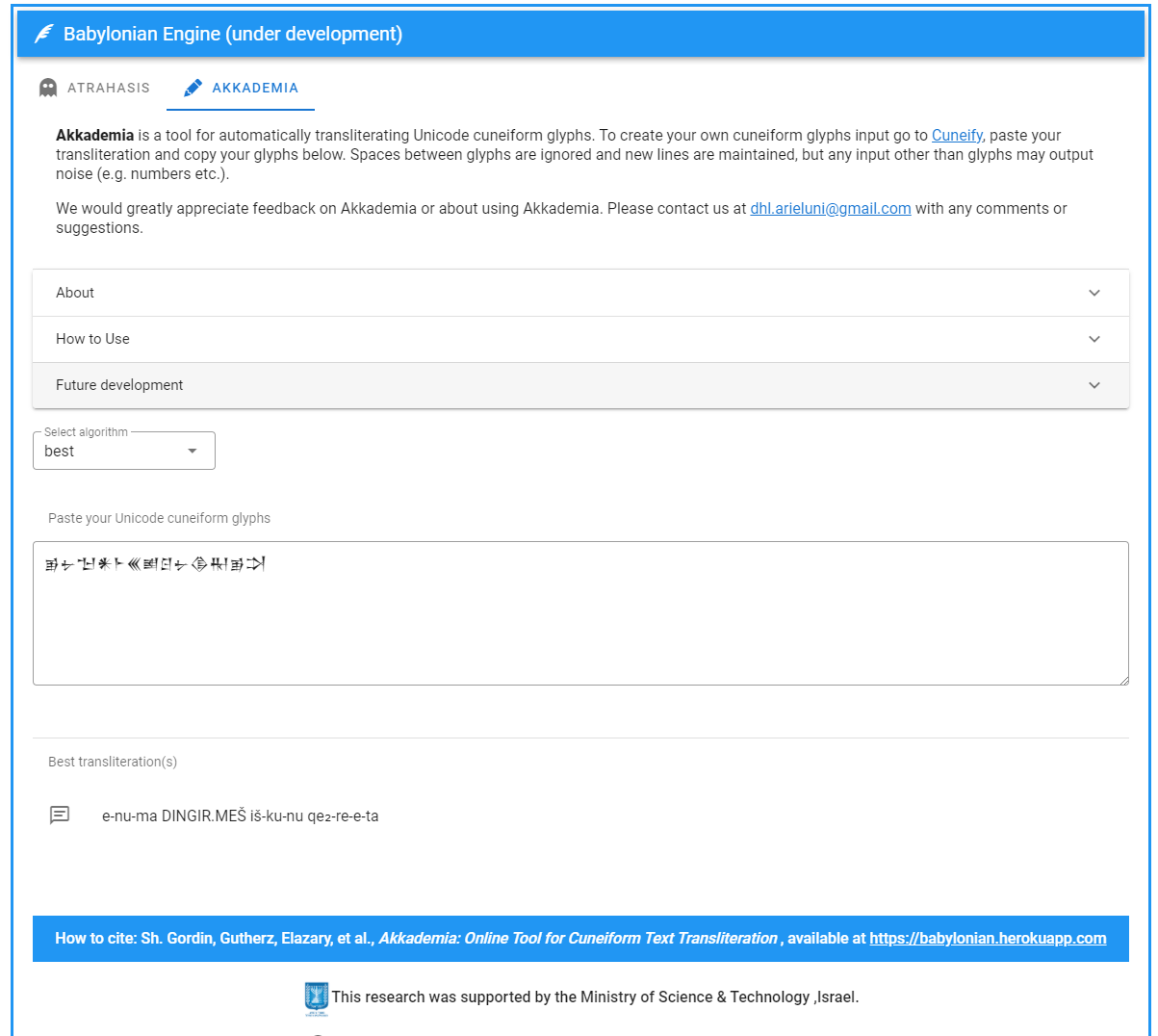
うわマジか。
出力された結果がこちらです。
e-nu-ma DINGIR.MEŠ iš-ku-nu qe2-re-e-ta
単語の分割、シュメログラムの判別、読みの選択も完璧です。これは予想以上の結果でした。
念の為もう1行見てみましょう。同じく「ネルガルとエレシュキガル」から第2行です。
𒀀𒈾𒀀𒄩𒋾𒋢𒉡𒀭𒊩𒌆𒆠𒃲𒅖𒁍𒊒𒌉𒈨𒊑
a-na a-ḫa-ti-su-nu dEREŠ.KI.GAL iš-pu-ru DUMU-šip-ri
彼らはエレシュキガルに使いを出した。
Nergal And Ereškigal (SAACT VIII)
ここでは𒀭𒊩𒌆𒆠𒃲 エレシュキガルという神名がシュメログラムで書かれているのと、mār šipri(使者)がシュメログラム混じりでDUMU-šip-riと書かれているところがポイントになるでしょうか。なおここでエレシュは𒊩𒌆の2符号で書きました。実はこの字は𒎐 U+12390 CUNEIFORM SIGN NIN9と符号化されて1字で書くこともできるのですが、ユニコードに収録された2014年とやや新しいので、古いデータでは使われていないことが多いのです。今回使っているフォント(Sinacherib)にも入っていないですね。
さてさて、その結果は……。
a-na a-ha-ti su-nu {d}-nin-{KI} gal iš-pu-ru DUMU.šip-ri
なるほど。ほぼほぼうまく読めているのですが、神名エレシュキガルをdninKI galと読んだわけですね。ディンギルを限定符として正しく読めているわけですし、間違いともいいきれないわけですが、やや残念です。学習元がRINAP(新アッシリア時代の王碑文)だからエレシュキガルがあんまり出てこなかったのかな……とOracc (opens new window)で検索してみると、ereš-ki-galの文字が登場するのはティグラト・ピレセル三世の碑文に一度 (opens new window)だけ。なるほどなー。なお𒊩𒌆を𒎐にしたものも試して見ましたが、{d}-nin-{KI}が {d}-u₂ {KI}になってしまいました。𒎐をu₂とは読まないはずなので、Akkademia君もこの文字は知らないのかもしれません。
とはいえこの2文だけでもAkkademiaの実力は明らかです。ではこの論文でどのような手法を使ってこの変換精度を生み出したのか……については、一旦稿を改めることにします。今日はここまで。
続きを書きました。